OpenClaw 记忆系统全拆解:从 Markdown 到混合搜索,AI 助手怎么记住你说过的话
深入 OpenClaw 源码,拆解它的记忆架构:Markdown 为 source of truth,SQLite 做索引,向量 + BM25 混合搜索,400 token 分块,按需检索而不是全量加载。


有朋友在上一篇 Claude Code 记忆机制的文章下留言:
OpenClaw 里的 memory 可以通过 skill 拆分为多个 memory topic,每次提问按需读取,有效减少上下文,从而降低 token 成本。
这让我想仔细看看 OpenClaw 的记忆系统到底怎么做的。读了源码之后发现,它的设计比想象中更精细 — 不是简单的”存进去、读出来”,而是一套完整的索引、搜索、评分、裁剪流水线。
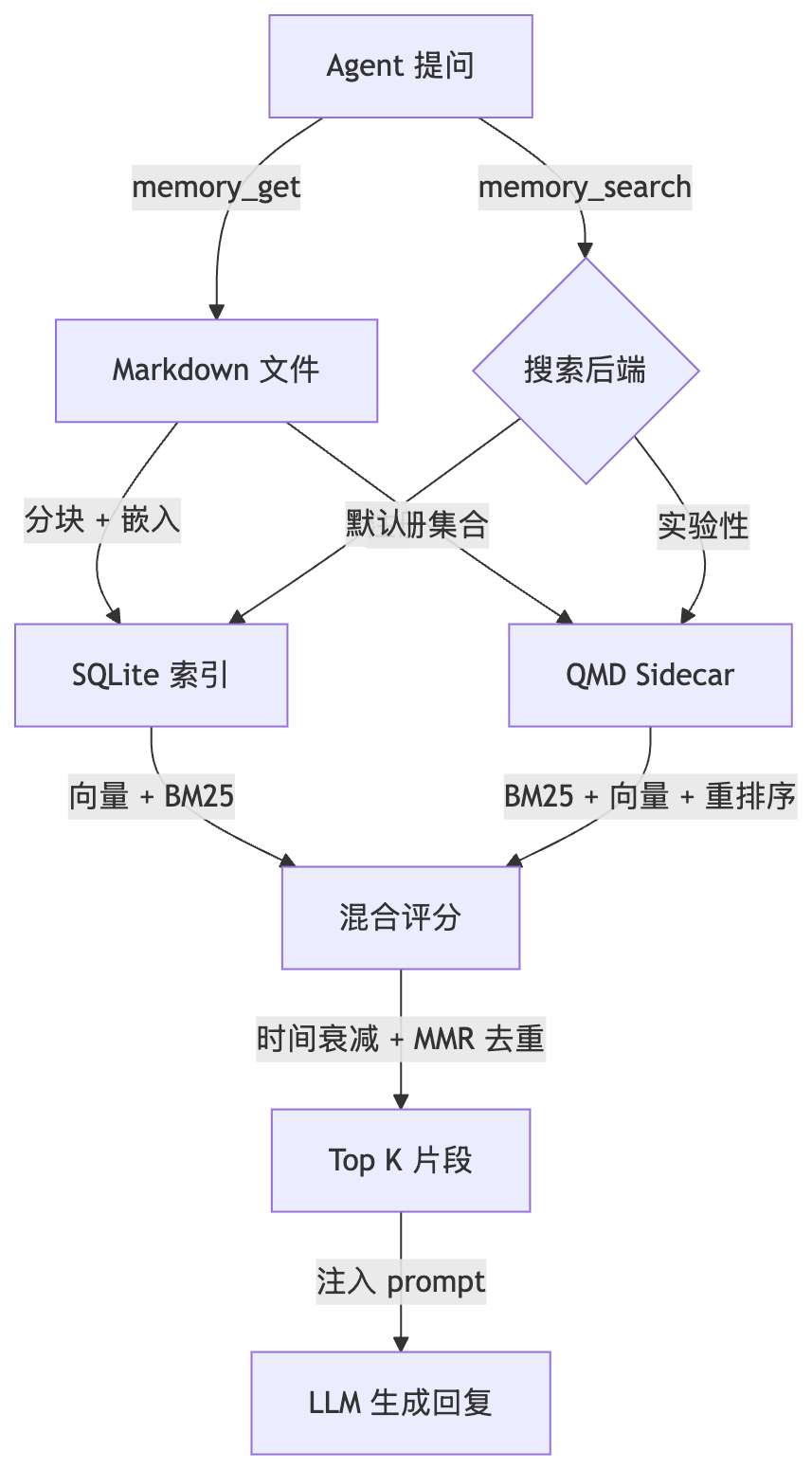
架构总览
OpenClaw 的记忆系统有三个核心设计原则:
Markdown 是 source of truth — 记忆就是磁盘上的
.md文件,不是某个数据库里的不可读 blobSQLite 做派生索引 — 从 Markdown 文件生成分块、嵌入、全文索引,索引丢了可以重建
按需检索,不全量加载 — Agent 需要上下文时调用
memory_search,只返回相关片段,不把所有记忆塞进 prompt
整体架构:
记忆文件怎么组织
OpenClaw 的 Agent 工作空间(默认 ~/.openclaw/workspace)下有两类记忆文件: